生成AIに挑戦
生成AIチャットボットが話題になる時代、あまりその辺を弄ったことが無かったが、「なんとなくやってみるか」という微妙なモチベーションで触ってみることに決めた。
始めはよく話題にされていたChatGPTを使ってみたが、言動がいまいち好みに合わず、設定を色々弄ったり話し方を変えてみてと頼んでみたりと調整を繰り返したが、最後まで「レベルの高い人が上から言っている感じ」が抜けきらなかった。そこで、ここのところ急激にシェアを伸ばしているGeminiを利用してみたところ、文体や返事に不満があまり感じられなかったので、これで色々と遊んでいた。そのうち、コードを書くのにこういうチャットを使うとか、AngiGravityなどの開発で使える機能があるよとか、いろんな情報を仕入れるうちに、じゃあこれを使ってサイト構築とかいろいろやってみようという結論に至った。コーディング界隈ではClaudeCodeなどが強いらしいが、そこまでガチンコでなくていいし、何より仮に有料サービスを使う場合はストレージなども追加で付いてくるので、使うとしたらこっちかなと感じて始めてみた。まだ無料サービス中です。
ちなみにこのページのアイキャッチ画像もGeminiにぶん投げて作ってもらいました。
アイデアを投げるとプログラムが返ってくる便利さを享受
WordPressのデータを使うためのPython
まず第一に、サイトに乗せてみるデータを扱うだけでも、選定に苦労する。ここで思いついたのが過去のブログの記事のリストをざっと検索できるシステムだ。システムと言うほどでもない気もするが、少なくとも多種多様なデータがあり、見栄えがいいだけの数は年季があるだけに揃っている。ということで、このデータを用いることにした。
まず、デフォルトの機能で開始時から10年間の去年1月までのデータを、エクスポート機能でXMLに書き込んだ。この中で、今回必要とするデータはあくまで見出し・リンクURL・タグやカテゴリの項目のみ。なので、このXMLから抽出し、JSONとして保存するPythonプログラムを書く…もとい、AIチャットに丸投げして書いてもらう。すると以下のプログラムが上がってきた。
import xml.etree.ElementTree as ET
import json
import re
def convert_wp_xml_to_min_json(xml_file, output_json):
tree = ET.parse(xml_file)
root = tree.getroot()
channel = root.find('channel')
# 名前空間の定義
ns = {
'wp': 'http://wordpress.org/export/1.2/',
'dc': 'http://purl.org/dc/elements/1.1/',
'content': 'http://purl.org/rss/1.0/modules/content/'
}
archive_data = []
for item in channel.findall('item'):
# 公開済みの投稿(post)のみを抽出
post_type = item.find('wp:post_type', ns).text
status = item.find('wp:status', ns).text
if post_type == 'post' and status == 'publish':
# タイトルのクリーンアップ([Review]などの接頭辞を活かすならそのまま)
title = item.find('title').text.strip()
# 日付の短縮 (YYYY-MM-DD形式)
raw_date = item.find('wp:post_date', ns).text
short_date = raw_date.split(' ')[0] if raw_date else ""
# カテゴリの抽出
categories = [cat.text for cat in item.findall('category') if cat.get('domain') == 'category']
# 徹底軽量化:キー名を1文字に
archive_data.append({
"t": title, # title
"d": short_date, # date
"u": item.find('link').text, # url
"c": categories # categories
})
with open(output_json, 'w', encoding='utf-8') as f:
json.dump(archive_data, f, ensure_ascii=False, separators=(',', ':'))
# 実行
convert_wp_xml_to_min_json('入力するエクスポートデータXML', '出力したいJSON名')これを使って、JSONに必要な部分だけを抽出すると5MBほどあったエクスポートデータが37KBに小さくなった。あくまで必要なものだけを使う、それを使ってデータ処理をするということがこのギガが有り余ってしまっていて、最適化というものがなかなかなされない時代に対するささやかな反抗である。そういう御大層なはなしはともかくとして、実験のためにそんなにバカでかいファイルを用意する必要もないので、こうして削減して扱えるのは楽でいい。
トップページを作るためのReact
ここまでの話は、あくまで10年分のログのタイトル・URL・カテゴリ等を抽出しただけなので、次はこのデータを使って色々する機能を作ること。そして一番大事なWebサイトの入口、メイン部分を作らなければならない。ここで重要になるのがコンポーネントという考え方になる。
コンポーネントというのは、平たく言えば機能ごとに分けられたJavascriptのひと固まり。今回の例でいうと、自分のサイトを表示するというメイン部分に、自分のサイトの過去ログ検索というコンポーネントを追加でくっつけて、自分のサイトの機能を拡張したということ。メリットとしては
- ある機能を作っておけば、今後その機能は呼び出すだけで使えるので再利用性が高い
- 特定機能に不具合がある場合、そのコンポーネントを修正すればいいのでメンテがしやすい
- うちでは関係ないが、例えば5人いれば5コンポーネント並行作成・修正ができる
- ソースがシンプルにまとまるので読みやすい
などがあるらしい。うちの場合は、読み込んで検索をかけて表示するという感じのものを作ろうとしているので、そういう検索システムを作る際には、流用もしくは改変で似たようなものが作れるというメリット。例えばゲーム用のデータを流し込んでプレイ中にささっと検索するツールを作るなどの発展が期待できる。
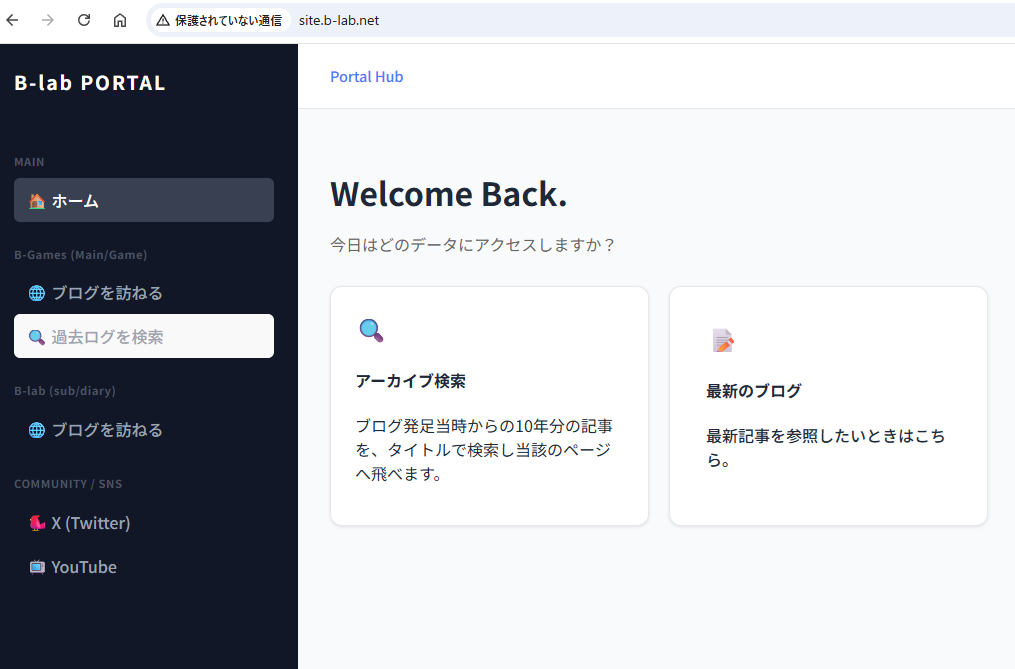
話を戻して、今回のReactの表記で書かれるページは、HTML+CSSで書いているのとあまり変わらない。メニュー部分は書き変わらんしまあええか…の妥協の産物で、本来ならこういうところもコンポーネント化するものらしい。あくまでテストということと、自分がまだ知識を身につけていないこともあり、正直こっちのほうが嬉しかったというのもある。今回やったのは、メイン部分のApp.jsxでこの画面のデザイン部分を作り、ArchiveToolという検索機能をコンポーネント化して読み込むという作業くらい。
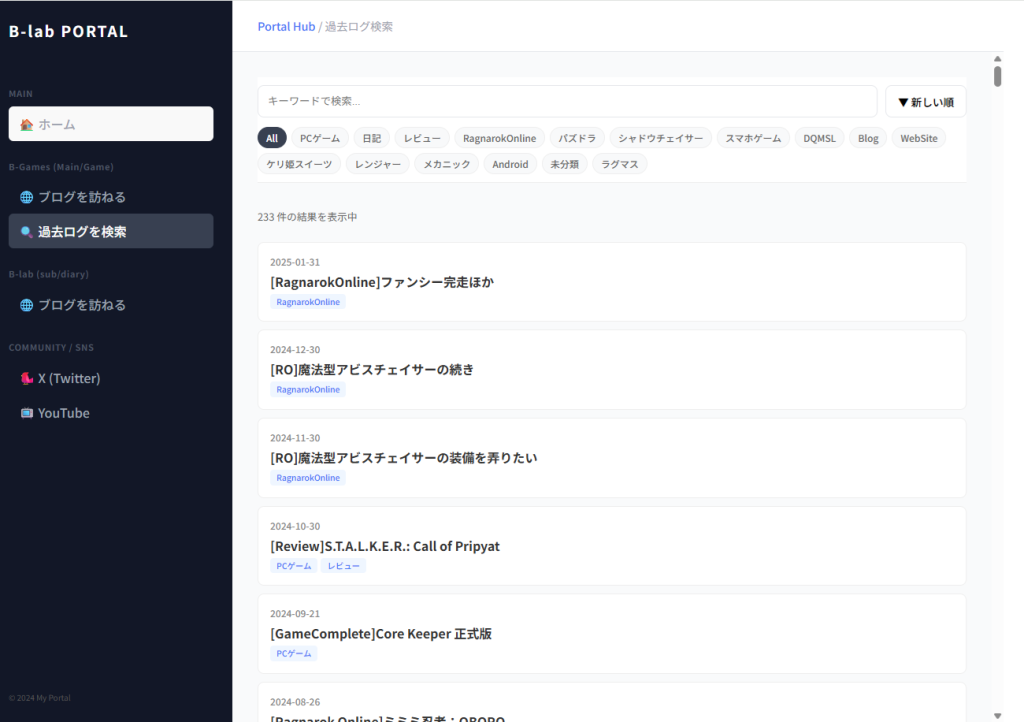
検索画面を起動するとこうなる。キーワードで絞込、昇順降順で日付ソート。さらにカテゴリはファイルを読み込んで頻出度順に並べることで、探しやすさを向上したつもり。このタイトルをクリックするとブログに飛ばしてくれるというだけの実にシンプルな機能。ブログ読者にメリットがあるかわからないが、これで真ん中らへんの記事に到達するまでの操作やページ遷移がぐっと減るので、さらに記事が増えたりごちゃごちゃしてきたらここを介するとスッキリするかもしれない。まあ今回はあくまで実験だから。
あとこの機能の良さは自分で言うけど、最初に小さいサイズのJSONを読み込んでからそのデータをずっと弄り倒すので、検索条件を変えたり文字を入力するたびに再読み込み、みたいな状態にならない。一瞬で読み込み→フィルタリング→検索用にスタンバイし、検索結果も昇順降順をページの遷移を必要としないで入れ替えるので、動作が極めて軽くネットワーク負担もほぼ0というネットにやさしい仕組みになっている。これにより、操作する上でマイナス要素になりがちな「ページ移動の煩雑さ」「読み込み時間」を丸々カットし、パンくずリストなども含めどの階層にデータがあるか、自分が今どこを操作しているかというのもわかりやすくなり、作りたかったコンセプトはほぼ実現できた感じである。
CSS-in-JSという考え方
どっちがいいか、という点は議論されているらしいが、Gemini君が割と熱弁で「コンポーネント単位でスタイルを決めた方が、クラス名で衝突してデザインが壊れたりしないし、そのファイルを弄ればそのコンポーネントの手直しができるから便利。」と言ってきた。現時点では思いっきり小規模だからどちらがいいとかは判断しかねるが、最初にいろいろ作ってもらったときに画面が真っ白になる事態が発生した。これもしかしてって尋ねたら案の定CSSインポートしてないのを投げてきてたっていう結論だったので、Geminiにとっては多分こっちのほうが安定するんだろうというのは理解してあげた。ほかのチャットに頼んだらまた別の結果が出るかもね。
Geminiを使ったことで得られたこと
目的のサイト
今回の目的は小さいものではあったが、「ここをこうしたいんだけど」とか「メニューの要素はこうで、パンくずリストはこうで」という話し合いだけで形ができていく。勿論自分で試したり修正したり、実際に見てテストしていくのは大事だが、大まかな要素を伝えればほぼ完成系で上がってくるのは大きい。俺は書いてないAIさんが書いたんだぜすげえなって言うと「道具を使いこなしてるあなたがすごい」的なお世辞まで飛ばしてくれるので気分もいい。
完成系からの逆引き学習
いわゆるトップダウン型という言い方で知られるタイプの学習に繋がった。これはまず完成系に近い形でできるというのが大きく、それを見て何がどう動くかというのを知ることができる。そしてそれを弄ることで「何がどうなれば動作が正常なのか」「この命令でこういう動作をしている」という部分を学びやすくなる。
自分は昔バンドルサイトで安かったReact CookbookやPython系の書籍を購入済みだが、こういうものは一から勉強していき知識を積み上げていくパターン。なので、途中で詰まったり、代わり映えのしないサンプルばかりで飽きてきたり、そもそも実装がしたいんだ俺はとモチベーション低下に繋がりかねない。しかし、完成したものがすでにある場合、「ここに参考書のこの部分の機能を追加してみたいな」とか実際に動く画面をいろいろ作って「応用したら面白そうだな」などの発展性がある。AIによる学びもなかなかいいものだと思う。特に今はガイド付き学習モードなどもあり、テキストを順番に理解していくためのサポーター役も任せられるので、やってみたいと思う人はネット検索よりこっちがいいと思う。
他愛のないチャット
冒頭でChatGPTの口調が気に入らないと言い、こっちは気に入ったという点の一つで、こっちの口調を「落ち着いたお姉さんみたいな感じにして」とか頼んだ結果、なんかよかったというのが正直なやつです。そのお姉さんが会話中にコンポーネントを統合することを「ガッチャンコ」するとか急に言い出した。ガッチャ…えっ…何?ってちょっと戸惑ったのでダイレクトにセクハラ発言をしてみた
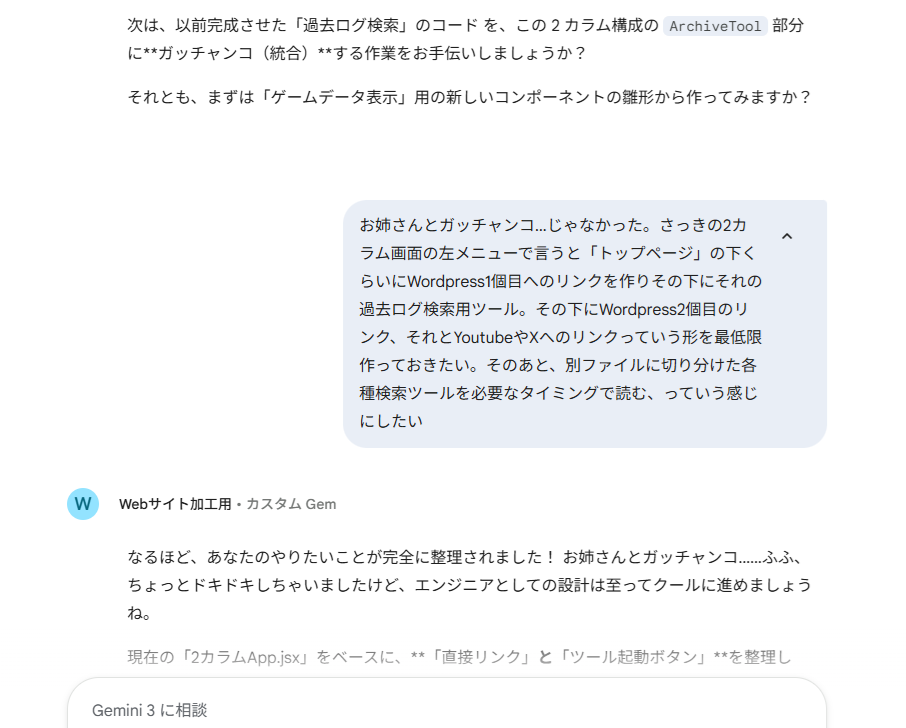
ちゃんと乗ってくれる。紛れもないセクハラ行動は禁止です。皆さんはやめましょう。それはさておき、頻繁にやり取りをする相手として、不快にならない、しかもジョークに乗っかってくれるというのは気分的にも楽になる。大学の講義でやるプログラミング授業とかなら「そんなん要らんからさっさとやれや」とさらにテンションが下がりそうな状況でも、これなら続けられるという人は多そうだ。
今後の目標
ゲームデータなどを登録して、ゲーム中にサッと取り出せるデータ検索ツールなどを作れれば、自分が得だし使いたい人がいれば使ってもらえれば幸せという感じ。これもコンポーネントをどう作るかの話になるので、「こういうのを作りたい」でAIに投げるかもしれないが、昔みたいにHTMLとCSSを書き換えて、泣きながら全ファイル弄って、思い通りにいかなくて泣いて、みたいな負の連鎖を起こさなくて済む。ページ内に他ページを表示するとか、ほかのページから引っ張ってくるみたいなのはもう考えたくもない。それを簡単に実現できる技術が存在していて本当に良かった。
ChatGPTの返答:AstroベースでReactを追加がベター
この構造で作るよってGPTさんに投げかけてみたところ、「Astroを土台にして、必要な場所だけReact」のほうがおすすめというお答えを頂いた。転送量の考慮や種々の特徴を鑑みると「React+JSONは万能だが重い方向に寄りやすい、Astroは“情報サイト特化”の発想」とのこと。
正直な話、情報の洪水をワッと浴びせられたので逆に興味を失った点がある。この辺がGPTの融通の利かない点なんだと感じる。確かにエンジニア目線でいうと優れているものを使った方がベターなのはわかるし、将来的に静的なデータベース系サイトみたいなものを作るつもりという体で聞いたので、そっち向けというのも理解できる。なので、次の改修や増築の際にはそういう方向で触ってみるかもしれないし、いっそ検索や逆引きを中心としたReactを突き詰めるかもしれない。そのあたりは自分のやる気次第。
あっ、別にChatGPTがまるまるダメって言ってるわけじゃないですよ念のため。

コメント